
딥러닝의 올바른 학습의 방향 - Regularization
딥러닝의 학습 목적이라고도 할 수 있는 일반화(Regularization)에 대해서 알아보자.
먼저 머신러닝에 쓰이는 전략 중에는 Test Error의 감소를 위해 설계된 것들이 많다. 심지어 훈련오차가 증가하는 대가를 치르더라도 Test Error를 줄이려는 전략들이 많이 있다. 이런 전략들들은 모두 Regularization 이라고 한다. 다시 한번 더 정리하면 Training Error를 줄이는 것이 아니라 Test Error를 줄이기 위해 학습 알고리즘에 가하는 모는 종류의 수정을 Regularization 이라고 할 수 있다.
딥러닝에서 대부분의 Regularization 전략은 일반화 추정량에 기초한다. 한 추정량의 일반화는 bias를 늘리는 대신 variance을 줄이는 방식으로 이루어진다. 즉 목표는 bias를 너무 증가시키지 않으면서 variance을 크게 줄여야 한다.
그러면 어떠한 일반화 전략들이 있는지 살펴보도록 하자.
1. Parameter Norms Penalties
L1 & L2 Loss fuction
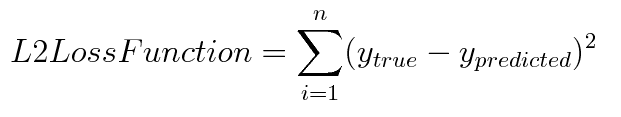
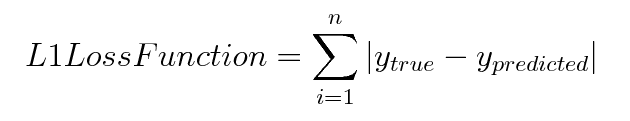
L2 loss fuction을 보면 실제값과 예측값 오차의 제곱을 해주는 형태이다. 에러에 대한 패널티를 훨씬더 크게 설정한다고 볼 수 있다. 만약 outlier가 들어온 경우를 보면 L2의 경우에는 훨씬 더 패널티를 많이 받게 된다고 볼 수 있다. 모델의 Robustness의 관점에서 보면 L1 보다 L2가 더 떨어지는 셈이다.(Robustness는 이상치나 노이즈가 들어와도 크게 흔들리지 않는 것을 의미) outlier에 대한 영향을 적당히 무시하고 싶다면 L1 loss 를 이용하고, outlier를 충분히 고려해야 하는 상황이라면 L2 loss를 활용 할 수 있을 것이다.
L1 Regularization & L2 Regularization

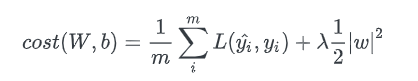
학습 시 사용하는 Loss fuction에 L1 or L2 Regularization가 더해진 식이다. 람다는 L1/L2 의 가중치다. 커질 수록 Regularization 비중을 높인다는 의미이다. 위에서도 언급했지만, 분산의 관점에서 더 설명하면, L2 Regularization의 경우 “입력된 데이터의 분산이 실제보다 더 크다” 라고 느끼게 만든다. 그래서 그 분산보다 낮은 분산을 갖는 feature들의 가중치를 감쇄시킨다.
2. Data Augmentation
학습의 일반화 성능을 개선하는 최선의 방법은 더 많은 자료로 학습을 하는 것이다. 하지만 현실에서는 당연히 데이터의 양은 제한적이다. 그래서 데이터를 가짜로 만들어서 학습을 시키는 방법을 사용하곤 하는데, 이때 주의해야 할 점은 가짜 데이터를 생성할 때, 가짜 데이터라 하더라도 데이터의 라벨링은 유지되어야 한다는 것이다.
또한 실제 학습 과정에서 데이터 증강 시 주의할 점은 데이터를 online 으로 데이터를 생성하고 여러 종류의 증강을 통해서 epoch가 진행되는 와중에도 지속적으로 한번도 본적이 없는 데이터를 네트워크에 입력해주어야 한다. 물론 일일이 확인할 수는 없지만, 이러한 데이터 증강의 아이디어를 이해하여야 한다. 핵심은 batch size 단위로 학습을 하는데 있어서 다양한 특성의 데이터를 입력으로 넣어줌으로써 데이터 도메인별로 가질 수 있는 특성들은 무시하고 핵심이 되는 feature만 학습이 되게끔 유도하는 것이다.
3. Noise Robustness
데이터 증강의 하나로 입력 데이터에 Noise를 적용하는 방식도 있다. 하지만 특히, Noise를 은닉단위에 추가하면 굉장히 강력한데, Dropout 방식이 그러한 Noise의 응용 방식이다.
Noise를 입력이 아니라 weight에 더하는 방법도 있다. 기본적으로 순환신경망(?)에서 많이 쓰였고, 이 기법을 가중치들에 대한 베이즈 추론의 확률적 구현으로 생각할 수 있다. 불확실성을 반영하는 하나의 확률분포를 통해서 가중치들을 표현하는 것이다.
마지막으로 출력 타겟에 Noise를 추가하는 방법이 있다. 예를들어 Label smoothing은 네트워크가 over-confident한 상황을 방지한다. 0,1 binary classificiation 상황에서 정확하게 1,0 을 예측 하도록 학습이 된다. 그러나 이것은 0 또는 1로써 100% 확신한다는 것임을 의미하는데, 반드시 그렇지는 않을 수 있다는 것이고, 확신을 못가지면 못가지는 만큼의 결과를 내는 것이 합당하다는 것이다. 그래서 [0,1] 사이에 Range를 두어서 0.9 혹은 0.6 등의 값을 가질 수 있도록 label을 smoothing 해주는 것이다.
4. Semi-Supervised Learning
딥러닝의 경우 데이터 수량 자체의 부족 문제도 있지만, 데이터가 많다 하더라도 Labeling에 대한 비용문제로 훨씬 더 큰 부분을 차지 한다. 이런 상황에서 SSL을 적용하여 문제를 해결 해 볼 수 있다.
여기서는 Regularization 관점에서 SSL을 바라보자. 자 기존에 갖고 있는 labeld 데이터가 기본 학습 방향이라면 unlabled 데이터는 데이터의 특성을 학습하는 데 기여할 수 있기 때문에, labled 데이터만으로 학습하는 것 보다는 unlabled 데이터도 함께 학습에 기여하면 일반화 성능을 올릴 수 있다는 것이다.
5. Multitask Learning
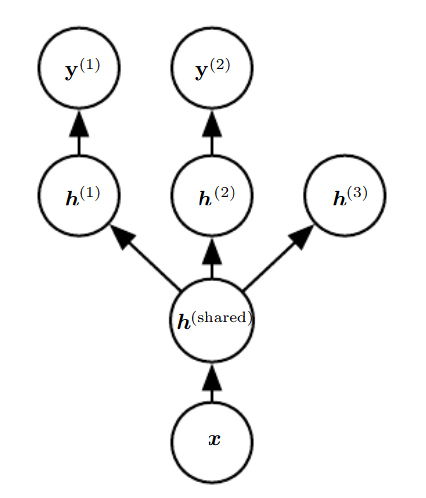
Multitask Learning은 여러 과제에서 발생한 weight 공유함으로써 일반화 성능을 개선하는 방법이다. 물론 이것은 서로 다른 과제들 사이의 통계적 관계가 유효하다는 가정이 성립해야 한다. 특정 과제의 변동 요인이 다른 과제와 연관이 있다는 아이디어이다. 그림에서는 아래쪽 layer가 weight 공유를 하고 있는 것이라고 볼 수 있다.
6. Early Stopping
딥러닝에서 Training에 대한 Loss값은 지속적으로 0으로 수렴해 간다. 하지만 Validation의 Loss는 Training Loss와 함께 줄어나가다가 어느 시점에서는 다시 증가하는 형태를 보인다. 이러한 현상을 Overfitting 이라고 하며, Validation의 Loss가 가장 낮은 시점에서의 Model을 save하게 된다. Early Stopping은 학습의 효율적 관점에서 필요한 하이퍼파라미터라고 생각한다. 다만, 여기서 중요하게 생각해보아야 할 것은 Validation 데이터를 어떻게 구성하냐에 따라서 Overfitting 지점이 달리 나타날 수 있다는 것이고, 모델의 save point가 달라질 수 있다는 것이다. Cross Validation을 통해서 학습 데이터 도메인의 데이터 분포에 대한 Variance를 비교해 볼 수는 있겠지만, Cross Validation 결과가 비슷하다고 해서 일반화 성능 또한 동일하다고 할 수 있는 것인지는 생각해볼 여지가 있다. 일반화 성능을 보기 위해서는 어떤 테스트 데이터를 사용하느냐에 따라서 수준이 정해지는 것이기 때문에 쉽지 않은 문제이다.
7. Bagging & Ensemble
Bagging(bootstrao aggregating)은 여러 모델을 결합해서 일반화 오차를 줄이는 기법이다. 서로 다른 모형을 따로 훈련하고 테스트 데이터에 대한 추론 결과를 모든 모델의 Voting 으로 결정한다. 이것은 일반적으로 Model Averaging 이라고 부르는 일반적인 기계 학습 전략의 한 예이다. 이 전략을 채용한 학습 기법들을 앙상블 학습법이라고 부른다.
앙상블 학습 방법은 모델의 조합에 따라서 여러 가지로 나뉘는데, 배깅 방식의 경우에는 같은 종류의 모델과 훈련 알고리즘, 목적함수를 여러 번 재사용할 수 있는 형태의 앙상블 방법이다. 그러니까 동일한 데이터 세트에 대해서 복원추출을 적용하여 K개의 데이터 세트를 만들어 내고 모델을 학습하는 방식이다. 이 방식의 경우에는 각 데이터 세트 별로 많은 수의 데이터가 중복이 된다고 예상할 수 있다. 이런 방식으로 학습을 하여도 충분히 다양한 해를 얻을 수 있다고 한다. 데이터 세트가 같더라도 무작위한 초기값이나 미니배치 및 하이퍼파라미터의 무작위 선택에 따른 차이나 네트워크의 비결정론적 구현에서 비롯된 차이가 크기 때문이다.
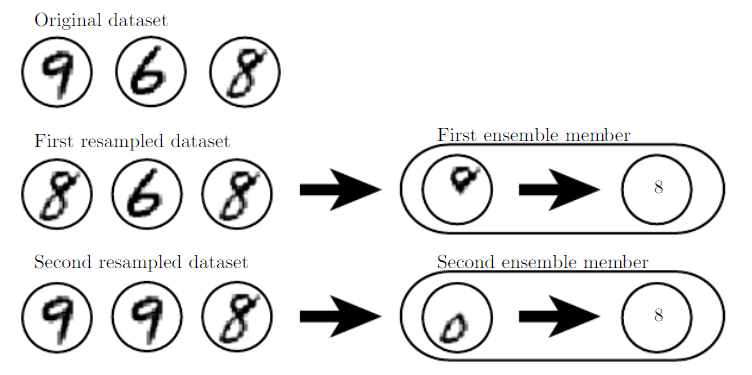
위 그림은 조금 더 bagging 방식의 효용성을 이해하는데 도움이 된다. 첫번째 샘플에서는 9가 없고 두번째 샘플 에서는 6이 없다. 그래서 네트워크에서 8을 구분 한다고 했을 때, 첫번째 샘플에서는 위쪽에 동그라미가 있는지 없는지를 볼 것이고, 두번째 샘플에서는 아래쪽에 동그라미가 있는지 없는지 볼 것이다. 개별적으로는 정확하다고 볼 수는 없는 방법이지만, 두 모델의 출력을 평균하면 안정된 결과를 얻을 수 있을 것이다. 결국은 동그라미가 위 아래 모두가 있을 때에 최대 확신도(maximal confidence)를 갖게 될 것이다.
8.Dropout
Dropout은 위에서 설명한 배깅 방식과 거의 비슷한 효과를 내는 방식이다. 배깅방식은 동일한 데이터 세트를 이용하여 다양한 해를 도출하는 모델을 만들고 그것들의 투표를 통해서 결과를 산출하여 일반화된 성능을 얻는다. 드롭아웃은 동일한 효과를 가져다준다. 네트워크의 마스킹을 통해서 가중치를 0으로 설정함으로써 인위적으로 연결을 끊는다. 이런 과정을 통해서 마치 배깅처럼 여러 개의 네트워크를 학습하는 효과를 얻는 셈이 되는 것이다.
아래 그림을 보면 그 형태가 잘 나와있다.
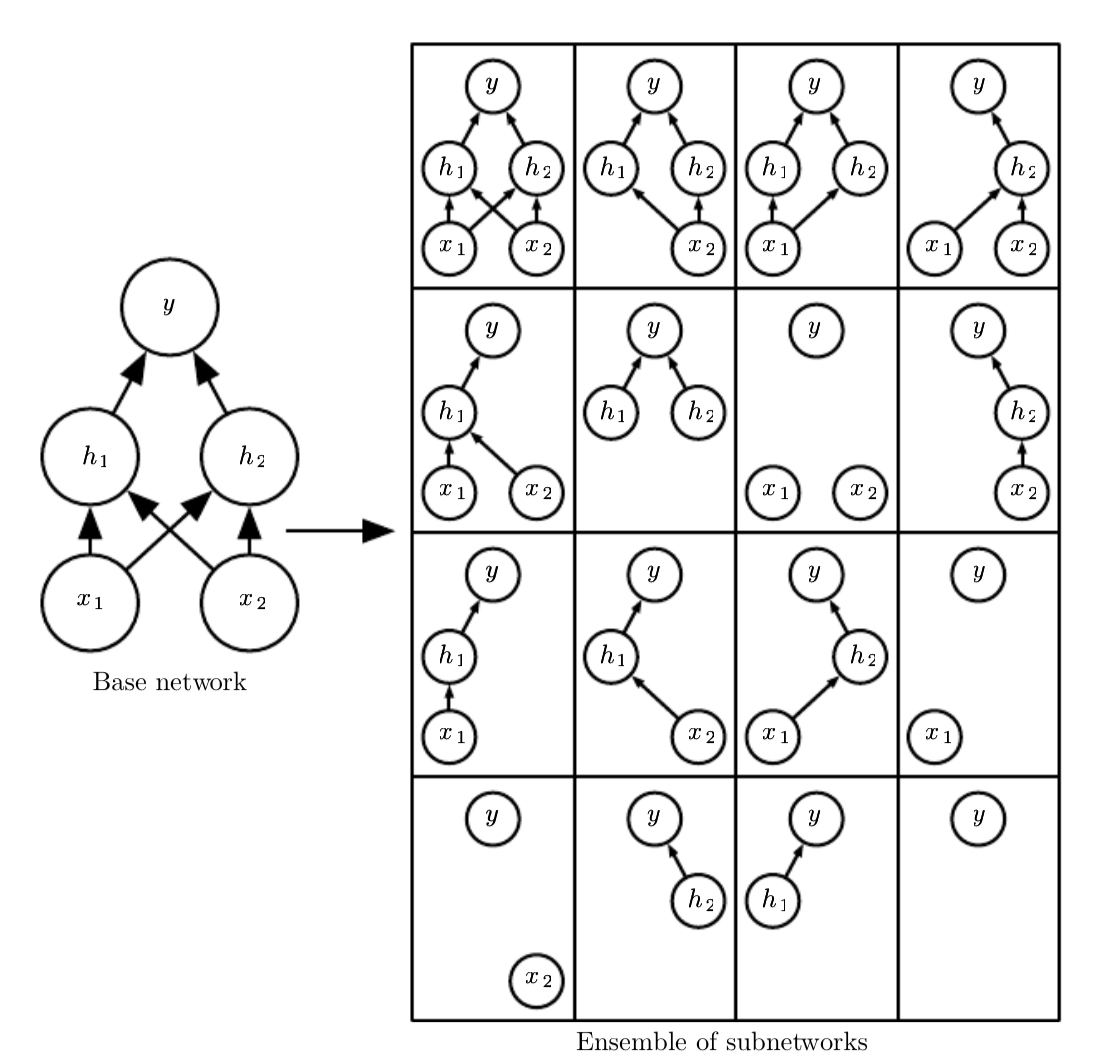
입력 단위와 출력단위가 무작위로 설정되는 것을 확인할 수가 있다. 다만, 입력과 출력이 전혀 연결되지 않는 경우도 보이는데, 이 경우는 네트워크의 크기가 크지 않기 때문에 발생하는 현상이다. 네트워크가 충분히 크다면 이러한 경우는 확률적으로 발생하기 힘들다고 보면 된다.
그러면 배깅방식과 드롭아웃의 차이점은 무엇일까? 그것은 배깅방식은 모델을 따로따로 학습을 시키기 때문에 매개변수들에 대해서 서로 독립적이지만, 드롭아웃의 경우는 하나의 네트워크를 학습할 때 노드만 선택적으로 죽여서 학습시키는 방식이기 때문에 매개변수를 서로 공유하게 된다. 한번 학습을 진행할 때 부분적인 네트워크만 학습하지만 매개변수를 공유하기 때문에 다른 부분 네트워크망도 적절한 매개변수를 가지게 된다. 또 배깅방식은 모델 수가 늘어날 수록 리소스에 대한 부담이 굉장히 커지게 되지만 드롭아웃은 계산비용은 조금 늘어나지만 하나의 모델을 만드는 것이므로 훨씬더 비용 효율적인 방식이라고 할 수 있다.
Reference
- http://www.chioka.in/differences-between-l1-and-l2-as-loss-function-and-regularization/
- https://afteracademy.com/blog/what-are-l1-and-l2-loss-functions
- https://seongkyun.github.io/study/2019/04/18/l1_l2/
- https://arxiv.org/pdf/1906.02629.pdf
- https://sanghyu.tistory.com/177
- https://www.deeplearningbook.org/